© Prof. Dr. Knut Barghorn, Jade Hochschule. Studienort WHV. E-mail: knut.barghorn@jade-hs.de
Das Ziel dieses Abschnitts ist, Ihnen einen Einblick in die Hardware von Computern und die Datenhaltung zu geben.
Sie sollen dabei lernen, welche Bestandteile ein Computer besitzt und welche Funktionen die einzelnen Bauteile haben. Dabei werden wir uns auf die wesentlichen Bestandteile beschränken. Wichtig ist, dass Sie die Arbeitsweise verstehen. Die technischen Details können an anderer Stelle vertieft werden.
Wir werden uns dabei der von-Neumann-Architektur annehmen. Sie haben bereits im 0-ten Abschnitt gehört, dass diese Architektur auch heute noch die Grundlage für die modernen Computer darstellt.
Damit Rechner, also die Hardware überhaupt arbeitsfähig sind, benötigt man Software. Wir werden uns der Software in diesem Abschnitt erstmal nähern, indem wir uns Betriebssysteme ansehen.
Anschießend werden wir und die Datenhaltung ansehen. Dabei werden wir zunächst solche Begriffe wie RAID, SAN und Fibre-Channel behandeln. In angewandter Form werden wir uns um Festplatten und Partitionen kümmern, damit Sie beurteilen können, wie sicher Ihr System wirklich ist wenn jemand zu Ihnen sagt: "Ihre Daten liegen auf einem RAID-0 System und sind damit absolut sicher. Denn egal ob aktuelle Redaktionsbeiträge, Archivdaten, Audio-/Videotechnik, Grafik & Animation oder systemkritische Internetanwendungen. Das Thema Datensicherheit und Datenlagerung ist wichtig. Jeder weiß, wie groß die Not ist, wenn die Festplatte auf einmal nicht mehr funktioniert.
Um eine Festplattenstruktur zu verstehen werden wir uns das Filesystem ext2 unter Unix ansehen. Dieses ist besonders gut zu verstehen und Sie werden danach in der Lage sein, Begriffe wie I-Nodes, Böcke und Superblock zuordnen können.
Die Grundlage heutiger digitaler Computer geht auf den Mathematiker John von Neumann zurück. John von Neumann fiel auf, dass die Programmierung von Computern mit Unmengen von Schaltern und Kabeln sehr langsam, mühsam und unflexibel war. Statt dessen schlug er vor, das Programm mit den Daten im Speicher eines Computers in digitaler Form zu speichern und die serielle Dezimalarithmetik, bei der jede Ziffer mit 10 Vakuumröhren dargestellt wurde, durch parallele Binärarithmetik abzulösen. In seiner Grundstruktur besteht ein Digitalrechner aus einem Verbundsystem von Prozessor, Speicher und Geräten für die Ein- und Ausgabe
Zusätzlich sieht die von-Neumann-Architektur noch die Verbindung zwischen diesen Bauteile vor. Diese wird über so genannte Busse realisiert.
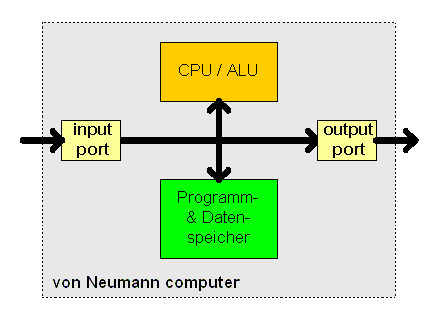
Bildquelle: http://www.sprut.de/electronic/pic/grund/cpu_neumann.gif
Der Prozessor oder auch die CPU (steht für Central Processing Unit -> Zentraleinheit) ist das zentrale Bauteil eines Rechners und damit sozusagen das Gehirn des Rechners.
Ein Programm muss sich im Hauptspeicher befinden, um von der CPU ausgeführt zu werden.Der Prozessor ruft die Befehle (Instruktionen) der Programme ab, prüft sie und führt sie nacheinander aus. Die CPU besteht aus Daten- und Befehlsprozessor
Der Datenprozessor ist zuständig für das klassische Verarbeiten von Daten und die Ausführung von Berechnungen. Der Datenprozessor enthält
- ein Rechenwerk, die so genannte ALU (Arithmetic Logical Unit), - und (mindestens) drei Speicherplätze (Register) zur Aufnahme von Operanden, die bezeichnet werden als Akkumulator (A), Multiplikatorregister (MR) und Link-Register
(L).Hinzu tritt in einigen Fällen ein viertes Register, das so genannte memory buffer register (MBR), das für die Kommunikation mit dem (Haupt-)Speicher notwendig ist.
Befehlsprozessor: Der Befehlsprozessor entschlüsselt Befehle und steuert deren Ausführung. Dazu bedient ersich der folgenden Komponenten:
1. Der aktuell zu bearbeitende Befehl befindet sich im Befehlsregister (instruction register,IR).
2. Die Adresse des Speicherplatzes, der als nächstes angesprochen wird, ist im Speicheradressregister (memory address register, MAR) vorhanden.
3. Die Adresse des nächsten auszuführenden Befehles wird im Befehlszähler (programcounter, PC) gespeichert.
4. Die Entschlüsselung eines Befehls erfolgt durch einen separaten Befehlsdecodierer.
5. Die Steuerung der Ausführung erfolgt durch das Steuerwerk.
Der Prozessor führt zu jedem Zeitpunkt genau einen einzigen Befehl aus. Der Befehl kann dabei nur genau einen Datenwert bearbeiten.
Die Speichereinheit ist in den modernen von-Neumann Architekturen eigentlich dreigeteilt.
1) Der Hauptspeicher. Bekannt auch unter dem Namen RAM
2) Dem BIOS (Dort finden sich die notwendigen Informationen um den Rechner zu booten)
3) Die Speicherlogik (Northbridge; steuert die Synchronisation der Datenflüsse zur und von der CPU.
Wir kümmern uns um den Hauptspeicher oder RAM (Random Access Memory)
Es gibt eine Vielzahl von verschiedenen RAM-Typen, die sich historisch nach und nach entwickelt haben. Der Nachteil ist, dass die RAM-Bausteine älterer Modellart in neuen Computern nicht eingebaut werden können.
EDO-RAM
SDRAM
DDR-RAM
RDRAM
Der Hauptspeicher dient dazu die Daten und Programme während des Betriebs des Rechners für die CPU vorzuhalten.
Hinweis: Die heute verwendeten RAMs sind volatil. Das bedeutet, dass wenn Sie den Rechner ausschalten gehen auch die im RAM gehaltenen Daten verloren. Das merken Sie spätestens dann, wenn Sie gerade einen längeren Text bearbeiten und den Rechner ausschalten ohne Ihr Ergebnis vorher auf der Festplatte zu speichern.
Dem Ein-/Ausgabewerk gehören z.B. der PCI-Bus für Einsteckkarten ebenso wie ein SCSI-Interface zum Anschluss von Peripheriegeräten.
Die Festplatte selbst oder auch die verschiednen Karten (Soundkarte, Grafikkarte etc.) und die Geräte Bildschirm, Scanner, Drucker etc. sind nach der von-Neumann-Architektur nicht Bestandteil des Rechners sondern stellen bereits wieder eigene Geräte dar.
Ein und Ausgabegeräte können vielfältig sein.
Eingabe: Tastatur, Maus, Joystick, Scanner, Barcodescanner, Festplatte...
Ausgabe: Bildschirm, Drucker, Festplatte
Die Ein- und Ausgabegeräte werden über die Southbridge mit dem Prozessor verbunden. Die Southbridge kann in einem Rechner auch weiter vom Prozessor entfernt sitzen, da die Geschwindigkeit des Datenaustausches nicht so gravierend ist, wie zwischen Prozessor und Hauptspeicher.
Wir haben im vorhergegangenen Teil einiges über die Verarbeitung von Dualen Zahlen in Rechnern gelernt. Mittlerweile ist uns auch klar, welche Hardware-Bestandteile einen Rechner ausmachen.
Ohne Programme, die die Hardware und die damit verbundene Verarbeitung steuern ist die Hardware aber nicht arbeitsfähig. Deshalb sehen wir und hier die Systemprogramme, und insbesondere das Betriebsystem näher an.
Systemsoftware kann man in zwei Klassen einteilen:
Ein Betriebssystem oder Operating System (OS) hat die Aufgabe, die Ressourcen des Rechners zu verwalten und schirmen die Anwendungsprogramme von den Eigenschaften der Hardware ab. Gleichzeitig stellen Betriebssysteme dem Benutzer und den Anwendungsprogrammen elementare Dienste zur Verfügung.
Top-Down-Sicht:
Abschirmung von der Komplexität und den Eigenschaften der Hardware. Das Betriebssystem ist für den Anwender und die Anwendungsprogramme leichter zu programmieren als die Hardware selbst.
Bottom-Up-Sicht
Das OS ist ein Verwalter und Koordinator der Komponenten. Es steuert alle internen Abläufe im Rechner (bei der Prozessverarbeitung), stellt Dienste zur Verfügung und sorgt für das Zusammenspiel der Komponenten (CPU, Speicher, Monitor, Drucker etc.)
Detailliert bedeutet dies, dass das Betriebssystem die Aufgaben
Beispiele:
Sie schreiben gerade einen Text am Rechner. Gleichzeitig hören Sie Musik, die Sie auf der Festplatte gespeichert haben. Der Drucker druckt gerade Ihre Tabellen, die Sie als Grundlage für Ihren Text benötigen.
Der Rechner muss also hier drei Aufgaben parallel bewältigen. Um dieses zu steuern und zu koordinieren, wird das OS benötigt.
Wenn Sie nun auch schon den Text ausdrucken wollen, obwohl die Tabelle noch nicht vollständig ausgedruckt ist, wird wieder das OS benötigt. Es muss sicherstellen, dass erst die Tabelle zu Ende ausgedruckt wird, bevor der Text ausgedruckt wird.
Dienstprogramme (Funktionen und Parameter des OS werden dem Nutzer direkt zugänglich gemacht. (Systemkonfiguration)
Das OS wird in der Regel auf der Festplatte gespeichert. Um das OS auf der Festplatte ansprechen zu können, wird aber eine weitere Software benötigt, das Basic I/O- System (BIOS). Dieses ist in der Regel auf dem Motherboard des Rechners in einem Baustein abgelegt.
Sie alle kennen das Betriebssystem MS-Windows und kennen die Fenstertechnologie dieses Betriebsystems. Es gab allerdings von der Zeit von Betriebssystemen mit Fenstern auch Betriebssysteme ohne Fenster und ohne grafische Benutzeroberfläche. MS DOS ist der direkte Vorläufer von MS Windows. Sie fanden noch unter Windows XP Programme wie AUTOEXEC.BAT und CONFIG.SYS, die es auch schon unter MS DOS gab. Mit Windows 7 und darauffolgenden Versionen wurden die Dateien aber ersetzt.
Was aber sind genau die Unterschiede zwischen einem Betriebsystem und einer grafischen Benutzeroberfläche?
Dazu sehen wir und die formalen Merkmale beider an.
Betriebssysteme haben verschiedene Aufgaben, die jeweils in Komponenten des OS zugeteilt werden können.
Wir haben oben gesehen, dass das Betriebssystem zuständig ist für die Verwaltung des Prozessors und ggf. die vorhandenen und zur Bearbeitung anstehenden Prozesse koordiniert.
Nun müssen wir aber noch ganz kurz definieren, was ein Prozess ist.
Definition Prozess (process, task): Ablauf eines Programms, der vom Betriebssystem verwaltet wird. Der Ablauf ist vorgegeben durch Befehle und Daten des Programms.
Ein Prozess hat folgende Eigenschaften:
Man unterscheidet grundsätzlich zwischen den Benutzerprozessen, die vom Benutzer gestartete Programme darstellen und den Systemprozessen, die Systemdienste erbringen (Mauszeiger bewegen, Drucken)
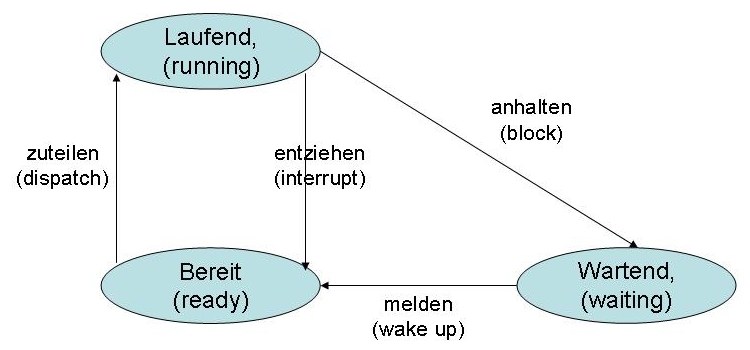
Ein Prozess kann sich gerade in verschiedenen Zuständen befinden. Der einfachste (uns für einen Prozess schönste) Zustand ist der Zustand „laufend“. In diesem Zustand ist ihm die CPU zugeteilt und er kann Befehle ausführen.
Der Zustand „wartend“ tritt dann ein, wenn der Prozess gerade auf eine Eingabe oder Ausgabe wartet. Während dieser Zeit wird einem anderen Prozess die CPU zugeordnet.
Das Anhalten des Prozesses wird vom Prozess selbst gesteuert. Alle anderen Übergänge zwischen den Zuständen werden durch Komponenten des OS (Dispatcher, Scheduler) bewirkt.
Das OS verwaltet die Prozesse in den Zuständen wartend und bereit.
Jeder Prozess ist in jedem Zustand auch löschbar. Damit kann der Prozess jederzeit aus dem System entfernt werden.
Wir haben oben gesehen, dass laufende Prozesse die CPU zugeordnet bekommen haben. Nach einer gewissen Zeit (Zeitscheibe) wird dem Prozess die CPU wieder entzogen. Dieses Verfahren nennt man Zeitmultiplexverfahren. Die CPU wird dann einem anderen Prozess zugeordnet.
Wenn ein Prozess gerade auf eine Ein-/Ausgabe wartet, würde er die CPU unnötig blockieren. Deshalb werden alle Prozesse, die gerade auf Ein-/Ausgaben warten in eine Warteschleife eingereiht.
Damit alle Prozesse in endlicher Zeit einmal zur Verarbeitung durch die CPU an die Reihe kommen, werden sehr lang rechnende Prozesse gelegentlich von der Verarbeitung freigestellt (suspendiert). Die Teilergebnisse der Prozesse werden dann auf die Festplatte ausgelagert (SWAP).
Unterbrechungen stoppen Prozessausführungen auf Grund von Ereignissen und starten sie ggf. nach der Durchführung der Ereignissbehandlung wieder. Dieses kann beispielsweise dann geschehen, wenn Zeitscheiben abgelaufen sind oder die Rückmeldung eines Ein-/Ausgabe-Gerätes die Prozessbearbeitung ein warten erzwingt.
Unterberechungen werden durch die Hardware generiert. In Sonderfällen aber auch durch den Prozess selbst (z. B. bei der Division durch 0)
Ablauf einer Unterbrechung
Unterbrechungsverarbeitung
Der Interrupt-Handler identifiziert den Typ der Unterbrechung und wählt ein Programm aus, welches für diesen Typ der Unterbrechung zuständig ist.
An dieser Stelle wird ein kleiner Einblick in die Welt der Filesysteme gegeben. Ausführlich läßt sich dieses Thema leider nicht im Rahmen dieser Vorlesung behandeln, da wir noch eine Vielfalt von weiteren Themen besprechen wollen.
Zunächst soll die Frage geklärt werden, was eigentlich ein Filesystem ausmacht.
Ein Filesystem (FS) ist der Teil des Systems, der alle Daten verfolgt, speichert und überwacht. Auf das Filesystem kann von anderen Teilen des Betriebssystems zugegriffen werden (z.B. über Anwendungen, Kommandos). Hardwaretechnisch kann ein Filesystem nur eine formatierte Einheit zur Speicherung von Daten sein (Festplatten, Disketten, CD-ROM etc.), verantwortlich für die Verwaltung ist ein Teil des Betriebssystems.
Linux arbeitet mit dem Filesystem ext2. Dieses ist das Standardsystem. Wir werden nachher noch sehen, dass Linux auch mit weiteren FS zurechkommt.
ext2 (extended Filesystem Version 2) ist der Nachfolger des FS extfs (extended Filesystem) und unterstützt im Gegensatz zu seinem Vorgänger Dateinamenlängen von bis zu 255 Zeichen, Dateigrößen bis zu 2 GB und Datenträgergrößen bis zu 4 TB. Mittlerweile existiert auch schon ext3, aber an den hier genannten Größen hat sich nichts verändert.
Jede Festplatte wird zunächst in Blöcke unterteilt. Diese Blöcke werden durchnummeriert. Die Blöcke werden dann in Gruppen unterteilt. In diesem Beispiel wird davon ausgegangen, dass die Festplatte genau eine Partition enthält.
|
Gruppe |
Block |
Funktion |
Beschreibung |
|
Gruppe 1 |
Block 1 |
Boot Block |
zum Starten des Systems |
|
Gruppe 2 |
Block 2 |
Superblock |
Information über die Größe der weiteren Gruppen |
|
Gruppe 3 |
Block 3 bis n1 |
I-Node-Bitmap |
Information (frei/belegt) über I-Node Blöcke |
|
Gruppe 4 |
Block n1+1 bis n2 |
Daten Bitmap |
Information (frei/belegt) über Daten-Blöcke |
|
Gruppe 5 |
Block n2+1 bis n3 |
Speicherplatz für I-Nodes |
je acht I-Nodes pro Block |
|
Gruppe 6 |
Block n3+1 bis n4 |
Speicherplatz für Daten |
je 1024 Byte pro Block |
Sind auf einer Festplatte mehrere Partitionen enthalten, so ist kein Boot-Block für jede Partition/ Filesystem nötig. Ein Superblock hingegen sehr wohl. Er enthält unter anderem Informationen über
Anzahl der I-Nodes
Anzahl der Blöcke
Anzahl der Blöcke I-Node-Bitmap
Anzahl der Blöcke Daten-Bitmap
Erste Datenzone
Blockgrößen
Aus der Tabelle können Sie entnehmen, warum der Datenträger manchmal voll ist, obwohl Sie nur sehr viele kleine Dateien gespeichert haben, die rechnerisch in der Summe der Dateigrößen nur einen Bruchteil der Plattenkapazität belegen.
Angenommen Sie haben genau 50.000 Datenblöcke (fiktive Zahl, entspricht etwa 200 MB-Festplatte), dann können Sie auch nur 50.000 Dateien speichern, weil jede Datei genau mindestens einen Block belegt, egal wie klein die Datei auch sein mag.
Zur Beruhigung: Die Blockgröße ist beim Partitionieren der Festplatte einstellbar. In der Tabelle wird eine Blockgröße von 1 kB = 1024 Byte angenommen. Dieses ist auch die Voreinstellung für das ext2-FS.
Sie sollten beim Partitionieren der Festplatte also darauf achten, dass die Blockgröße zu der vorwiegenden Anwendung der Festplatte passt. Bei großen Dateien (Videodateien) ist eine große Blockgröße vorteilhaft, da dadurch schneller von der Festplatte gelesen (und auch auf die Platte geschrieben) werden kann.
Bei normalen Arbeitsplatzrechnern ist eine Blockgröße von 1-4 kB meines Erachtens nach in Ordnung. Die Werte sind leider nur experimentell zu ermitteln. Hierzu gibt es einige Untersuchungen. Einfach mal bei einer Suchmaschine nach blocksize und ext2 suchen.
Weitere Vorteile größerer Blöcke sind:
schnellerer FS Check
schnelleres Booten des Rechners
Verringerung der CPU-Last bei Lese- und Schreibzugriffen großer Dateien.
Vorteil bei kleinen Blöcken:
keine Verschwendung von Plattenplatz bei kleinen Dateien
I-Nodes sind nichts anderes als die Adressen der Dateien. Für jede Datei wird ein I-Node angelegt. In 128 Byte werden dabei unter anderem folgende Informationen über die Datei abgelegt:
Dateieigentümer (ID des Nutzers und der Gruppe)
Informationen über Zugriffsrechte
Anzahl der Links
Zeitmarken (Erstellung, letzte Änderung, letzter Lesezugriff etc.)
Verweise auf die ersten 12 Datenblöcke die die Daten der Datei enthalten (weitere Datenblöcke -> neuer I-Node).
Da für jeden I-Node 128 Byte bereit stehen, werden acht I-Nodes in einen Block geschrieben.
Bei jedem Zugriff auf eine Datei wird der I-Node aktualisiert (Zeitmarken!) . Diese Information wird nicht gleich auf die Festplatte geschrieben, sondern erst einmal aus Performancegründen im Hauptspeicher zwischengelagert.
Wenn ein Server mit einem "normalen" Filesystem im laufenden Betrieb unkontrolliert abgeschaltet wird, werden die Daten des Hauptspeichers nicht mehr auf die Festplatte geschrieben. Dies führt zu einer Inkonsistenz des Filesystems. Die Inkonsistenz wird beim nächsten Systemstart erkannt und repariert.
Glücklicherweise gibr es für den Fall einer Inkonsistenz Prüfprogramme, die größeren Schaden verhindern.
Das Prüfprogramm e2fsck startet automatisch, wenn das System inkonsistent zu sein glaubt.
Im Superblock gibt es ein so genanntes Valid-Bit. Dieses Valid-Bit wird beim Hochfahren des Systems geprüft und auf Null gesetzt. Beim kontrollierten Abschalten des Systems wird das Bit auf 1 gesetzt. Erkennt das System beim Hochfahren eine 0, wird automatisch e2fsck gestartet, da angenommen werden muss, dass das System nicht ordnungsgemäß "runtergefahren" wurde.
Das System gibt dann foldende Meldung aus: /dev/hda5: was not cleanly unmounted, check forced
Eine andere Möglichkeit, warum e2fsck gestartet wird, ist gegeben, wenn das System eine maximale Anzahl von Bootvorgängen erreicht wurde ohne dass ein Filesystemcheck vorgenommen wurde.
/dev/hda5: has gone too long without being checked, check forced
Die maximale Anzahl von Bootvorgängen ohne Check kann mit dem
Befehl tune2fs
verändert werden. Näheres
dazu siehe man-pages.
e2fsck kennt mehr als 150 verschiedene Meldungen, die hier nicht alle besprochen werden können.
Der Check der Inkonsistenz kann sehr lange dauern. Bei einem Filesystem mit 50 GB Daten wird es normalerweise einige Stunden dauern, bis alle Inkonsistenzen aufgelöst sind.
Nachfolgende Information soll vor groben Fehlern schützen:
Sie sollten wissen, welche Festplatten-Partitionen es gibt und wie groß die Partitionen sind. Ferner, welche Daten darauf untergebracht sind. Dies ist selbstverständlich VOR einem Ausfall zu ermitteln und zu notieren.
Sie müssen die Informationen während des Boot-Prozesses lesen können und wissen, wie bei einem gewünschten Eingriff von Hand zu verfahren ist.
Es gibt 5 Hauptprüfläufe.
Pass 1: Checking inodes, blocks, and size : I-Nodes werden darauf geprüft, ob sie korrekte Daten enthalten. Fehler, die hier erkannt werden, sind z.B. unbekannter I-Node-Typ, falsches I-Node-Format, Verweise auf Datenblöcke, die nicht existieren oder die anderweitig referenziert werden.
Pass 2: Checking directory structure : Verzeichnisstruktur wird geprüft, d.h. die I-Nodes der Verzeichnisse müssen gültige Einträge haben. Verzeichnis-Einträge, die auf I-Nodes zeigen, die in Pass 1 als fehlerhaft erkannt wurden, werden entfernt.
Pass 3: Checking directory connectivity : Hier wird überprüft, ob es Verzeichnisse gibt, die nicht mehr mit dem Filesystem verbunden sind (z.B. durch ein CLEAR und ein REMOVE in den vorangegangenen Pass). Falls ein derartiges '''Loch" im Filesystem entsteht, können die darunter liegenden Verzeichnisse gerettet werden. Diese werden im Verzeichnis "lost+found" unter ihrer I-Node-Nummer abgelegt
Pass 4: Checking reference counts : In dieser Phase können nicht referenzierte Files aufgefunden werden. Auch hier werden die Dateien im Verzeichnis "lost+found" unter ihrer I-Node-Nummer abgelegt.
Pass 5: Checking group summary information : Die Listen mit freien Datenblöcken und benutzten I-Nodes werden mit den neu erstellten Listen verglichen, die in den vorhergehenden Phasen generiert wurden.
Der Check kann auch manuell gestartet werden. Dazu dient das Kommando fsck. In der Regel ist eine manuelle Prüfung aber nicht nötig.
Achtung: Prüfen Sie niemals ein Dateisystem, welches noch "gemountet" ist und noch geschrieben werden kann. Sie können sich vielleicht vorstellen, was dann passiert. Es werden immer mehr Inkonsistenzen gebildet, die nicht mehr korrekt aufgelöst werden können.
Noch ein paar Anmerkungen zum Filesystemcheck:
Es kann sehr lange dauern. Wenn Sie einige Checks gemacht haben, bekommen Sie ein Gefühl dafür, wie viel Zeit ein Check des bestimmten Systems in etwa beanspruchen wird und können Anfragen in diese Richtung qualifiziert beantworten. Alles Drängen des Chefs nütz nichts: Es lässt sich einfach nicht beschleunigen. Deshalb nicht nervös werden.
Auch wenn der Chef noch so sehr drängt und alles auf den Server wartet. Brechen Sie den Check niemals (in Worten "niemals") ab. Ein Abbruch macht alles noch viel schlimmer und danach sind Sie auch nicht arbeitsfähiger.
Vielleicht müssen Sie von Hand bestätigen, dass I-Nodes entsprechend geändert werden oder das Prüfprogramm fordert einen Neustart des Systems und schlägt den Check von Hand vor. Also: Papier und Stift mitnehmen und bitte nicht vertippen ;-)
RAID = Redundant Array of Independent Disk
Was genau sind eigentlich RAIDs?. Wie der Name schon sagt: mehrere Festplatten, die unabhängig voneinander funktionieren.
Zunächst unterscheidet man zwei verschiedene Vorteile von
RAID-Systemen. Sie wurden in den 90er-Jahren an der Universität
von Berkley entwickelt und dienen zur Erhöhung der
Ausfallsicherheit (Redundanz) bzw. zur Erhöhung der Lese- und
Schreibgeschwindigkeit (Striping).
Beide Vorteile gemeinsam zu
erreichen ist, wie Sie sich vorstellen können, schwierig. Wenn
die Redundanz erhöht wird, leidet die Geschwindigkeit. Die beste
Zugriffsgeschwindigkeit erreichen Sie, wenn Sie die Datenpakte auf
verschiedenen Festplatten halten, so dass zügig von mehreren
Platten gelesen werden kann. Die beste Redundanz erreichen Sie, wenn
identische Daten auf verschiedenen Platten liegen.
Grundsätzlich unterscheidet man die RAID-Syteme in Software-RAID und Hardware-RAID. Ein RAID-System besteht (normalerweise) aus verschiedenen Wechselplatten, die in 5 1/4 Zoll-Einschüben untergebracht sind. Mittlerweile gibt es aber auch schon kleinere Einschübe, die manchmal auch direkt im Gehäuse des Rechners untergebracht sind.
Ein Hardware RAID ist in der Regel eine externe Lösung. Eine Reihe von möglichst baugleichen Festplatten (optimal: Wechselplatten) wird von einem Hardware RAID-Controller gesteuert.
Es kann auch ein Hardware-RAID direkt in des Rechnersystem eingesetzt werden, aber der Austausch von Platten wird damit erschwert.
Ein RAID-Controller benötigt selbstverständlich eine betriebssystemspezifische Treibersoftware.
Ein angeschlossener Hardware-RAID-Controller verhält sich gegenüber dem Computer wie eine einzige Festplatte.
Hardware-RAIDs sind idealerweise über SCSI-Bussysteme anzuschliessen. Es funktioniert zwar auch über EIDE, aber der Datendurchsatz kann zu Problemen führen.
Ein Software-RAID-System hat den Nachteil, dass Server und Festplattensystem logisch nicht eindeutig getrennt sind. Ferner benötigt die Software des Software-RAID-Systems auch Systemresourcen und Memory.
Das Software-RAID kommt auch recht gut mit EIDE-Platten zurecht und erfreut sich daher immer stärkerer Anwendung bei Privatnutzern.
Aus diesen Gründen sollte bei systemkritischen Produktionsservern grundsätzlich ein Hardware-RAID-System verwendet werden.
Die RAID-Stufe (auch RAID-Level) sollte zuvor gut überlegt sein, da eine Umstellung normalerweise nicht unproblematisch ist.
Bei RAID-0 (Striping)werden die Datenblöcke abwechselnd auf die n vorhandenen Festplatten geschrieben (Strip Array), was die Lese- und Schreibperformance erhöht. Eine Datensicherheit bei Plattenausfall ist jedoch nicht gegeben. Wenn eine Platte defekt ist, sind sämtliche Daten verloren.
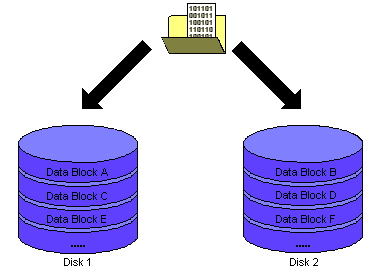
aus: http://www.ipcas.de/index.html
Bei RAID-1 (Mirroring)werden die Datenblöcke
immer parallel auf n Festplatten gleichzeitig
geschrieben. Diese sehr gute Datensicherheit erhöht jedoch nicht
die Lese oder Schreibgeschwindigkeit. Fällt eine Platte aus,
sind alle Daten direkt auf der/den andere(n) Platte(n) vorhanden.
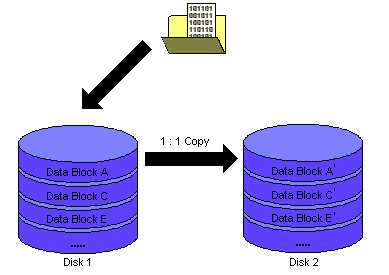
aus: http://www.ipcas.de/index.html
RAID-2, RAID-3, RAID-4 werden kaum genutzt.. Wie bei RAID-0 werden die Datenblöcke alternierend auf die n vorhandenen Festplatten geschrieben. Zusätzlich werden aber bei jedem Schreibvorgang auf eine weitere Festplatte die Checksumme der Daten der anderen Platten in den gleichen Streifen der Festplatte geschrieben. (Gleicher Streifen meint hier: gleiche Position der Platte; Zylinder, Block, Sektor). Benutzt für die Bildung der Checksumme wird das XOR-Verfahren. So können die Daten bei einem Plattenausfalls immer rekonstruiert werden. Fällt die Parity-Platte aus, kann es bei einem Datenverlust auf einer weiteren Platte sofort zu Problemen kommen.
Beispiel : Es gibt drei Platten. Auf die ersten beiden Platten werden an die Position Y Daten A und B geschrieben. Auf die dritte Platte wird an die Position Y die Checksumme C = A XOR B geschrieben.
Aufgabe : was ist ein XOR? Erstellen Sie eine Tabelle!
Bei RAID-5 wird es noch raffinierter. Hier werden die Checksummen (auch ECC (Error Correction Code)) genannt, auf alle verwendeten Platten verteilt.
Bei drei Festplatten und acht Datensätzen sieht die Verteilung aus, wie in folgender Tabelle dargestellt. Überlegen Sie, was passiert, wenn eine Festplatte ausfällt.
|
Platte 1 |
Platte 2 |
Platte 3 |
|
A |
B |
A xor B |
|
C xor D |
C |
D |
|
F |
E xor F |
E |
|
G |
H |
G xor H |
Es geht noch besser:
Bei RAID-6 wird
gegenüber RAID-5 eine weitere Platte für eine weitere
unabhängige Speicherung der ECC verwendet.
Es gibt noch weitere RAID-Varianten, die teilweise Spezialvarianten der genannten Stufen darstellen und oftmals aus Marketing-Gründen anders benannt werden. Als Literatur empfehle ich die Internetseite
Dort finden Sie ein kleines Applet, welches die Arbeitsweise von RAID-5 veranschaulicht.
Häufig wird bei den RAID-Systemen eine so genannte Spare-Platte benutzt. Diese Platte hat lediglich die Aufgabe, bei einem Defekt einer Festplatte sofort deren Dienst zu übernehmen. Solange alle Platten arbeiten ist diese Platte nicht im Einsatz, sondern dient als echter Ersatz.
Beispiel : Wenn 7 x 8GB-Festplatten in einem "RAID-5- mit Spare" verwendet werden, ergibt sich folgendes System: Brutto 7x8 GB = 56 GB, netto 5 x 8 GB = 40 GB. Gelesen und geschrieben wird auf 6 Festplatten gleichzeitig.
Aufgabe: Sie haben ein RAID-System mit 5 Festplatten je 40 GB. Welche Brutto- / Nettokapazität haben Sie bei den RAID-Varianten 0, 1, 5
Wechselplatten im RAID-Verbund (RAID 5 mit Spare)

Wenn eine Platte defekt ist, kann diese ausgetauscht werden. Ideal: Platten im Wechselrahmen, dort kann einfach eine baugleiche neue Platte eingesteckt werden. Danach beginnt die Rekonstruktion der Platte. Dieses kann unter Umständen sehr lange dauern, aber bei höheren RAID-Leveln kann trotzdem weitergearbeitet werden.
Für den Austausch von Festplatten im laufenden Betrieb sollte man auf eine "Hot Swap"-Funktionalität (auch "Hot-Plug" genannt) des Festplattensystems achten. Hierbei geht es um mögliche Spannungsspitzen, die durch das Herausziehen einer Platte erzeugt werden können und weitere Bauteile beschädigen können (z.B. SCSI-Bus). Die neue Platte wird dann sofort in das System integriert.
Achten Sie als verantwortlicher Systemadministrator mit ausfallkritischen Daten darauf, dass eine Hot-Spare Platte zur Sicherheit eingesetzt wird. Das erhöht deutlich die Genussfähigkeit von Wochenenden und Urlauben.
RAID 0 bietet höhere Performance, allerdings keine erhöhte Datensicherheit.
RAID-1 ist das System mit der höchsten Datensicherheit, verlangt aber auch den höchsten Aufwand. Die Performance ist nicht so hoch wie bei RAID-0.
RAID-3 bietet hohe Datensicherheit und hohe Performance
RAID-5 bietet höchste Datensicherheit und hohe Performance bei vergleichsweise gutem Preis/Leistungsverhältnis
Für die meisten Applikationen bietet sich daher RAID-1 oder RAID-5 an.
Weitere Informationen zu RAID: http://www.infodrom.north.de/~joey/Linux/raid/ix-9511.html
Sie haben gerade die verschiedenen RAID-Level kennen gelernt. Darunter wird das Speichersystem verstanden. RAID bezeichnet die Speicherung von Daten auf der Festplatte / den Festplatten.
Weil ein RAID-System in der Regel genau einem Server zugeordnet ist und über SCSI mit dem Server verbunden ist, muß das RAID-System nahe beim Server stehen. (SCSI-Spezifikationen siehe: http://martin.sluka.de/SCSI.html )
Um das RAID-System auch örtlich entfernt vom Server zu halten, wurde SAN (Storage Area Network) entwickelt.
SAN beschreibt eine Technologie zur verteilten, entfernten Datenhaltung. Mittels SAN wird ein Speichermanagement aufgebaut. Die Daten werden über ein eigenes Netzwerk in einem Speichersystem abgelegt. Dieses Speichersystem verwendet natürlich im Festplattenspeicher wieder RAID-Technologien.
Weitere Informationen zu SAN: http://www.tecchannel.de/hardware/679/0.html
Fibre Channel ist keine Speichertechnologie, sondern eine moderne Technik um schnelle Datenzugriffe zu erhalten und wird zur Realisierung von SAN verwendet.
Weitere Informationen zu Fibre Channel: http://www.tecchannel.de/hardware/679/1.html
Sie kennen die Begriffe SAN und Fibre Channel
Cloud beschreibt eine Technologie zur verteilten, entfernten Datenhaltung oder der Nutzung von Anwendungen, die nicht lokal auf dem Rechner liegen, sondern verteilt auf verschiedenen Server. Notwendig dazu sind Technologien wie
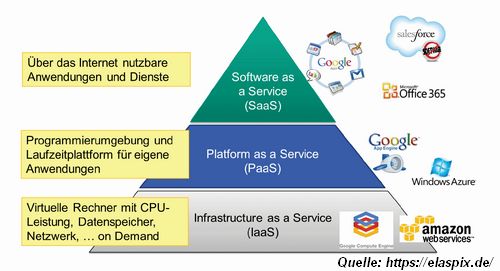
Um diese Begriffe letztlich richtig verstehen zu können, muss man tiefer in die Netzwerktechnologie einsteigen und Protokolle wie TCP und HTTP(S) verstehen. Das kommt in den folgenden Semestern.