© Prof. Dr. Knut Barghorn, Jade Hochschule. Studienort WHV. E-mail: knut.barghorn@jade-hs.de
In den vorangegangenen Vorlesungen haben wir uns mit den Grundkenntnissen der Informatik beschäftigt. Wir haben gesehen, dass der Begriff Algorithmus in der Informatik ein sehr zentraler Begriff ist. Im Kapitel „Einführung in Prozesse und Algorithmen“ haben wir die erst Begegnung mit diesem Begriff erlebt. Wir haben dort auch eine erste Begegnung mit einer Turing-Maschine gehabt. Wir haben dort gelernt, wie eine Turing Maschine aufgebaut ist und welche Aufgaben diese Maschine übernehmen kann. Im letzten Kapitel haben wir gesehen, dass bei der Lösung von Problemen durch Algorithmen Grenzen gesetzt sind.
Bei einigen von Ihnen ist vielleicht die Frage aufgekommen, wozu dieses Wissen Ihnen dienen soll.
Die Antwort darauf ist recht simpel: Sie werden hier ausgebildet, um später als Führungskraft zu arbeiten. Dabei wird man von Ihnen verlangen, dass Sie Prozesse optimieren oder neue Produkte in die Produktion aufnehmen.
Bei der Aufnahme neuer Prokukte in die Produktion müssen Sie sich über die bisherigen Prozesse im Klaren sein. Dazu müssen Sie die Abläufe in der Produktion der neuen Produkte festlegen.
Selbst wenn keine neuen Produkte angeboten werden, so müssen permanent die alten Produktionen darauf überprüft werden ob sie noch effizient sind.
Prozessoptimierung bedeutet auch Einsparung von Human Ressources und dadurch letztlich auch die Einsparung von Kapital.
Das wirft natürlich die Frage auf, welche Prozesse können denn überhaupt durch Maschinen (Computer) übernommen werden?
In diesem Kapitel werden wir uns also wieder den Prozessen zuwenden. Wir werden die Frage behandeln, wie solche Prozesse überhaupt beschrieben werden können. Die Informatik hat einige Darstellungsformen für Geschäftsprozesse hervorgebracht, um die wir uns in diesem Kapitel kümmern werden.
Sie werden in diesem Teil wieder einige Übungen und Hausaufgaben absolvieren, in denen Sie zeigen können, ob Sie das Wissen aufgenommen haben.
Das Thema Modellierung von Prozessen ist recht komplex. deshalb ist es zweckmäßig zunächst einmal ein wenig Ordnung in die verschiedenen Ebenen zu bringen.
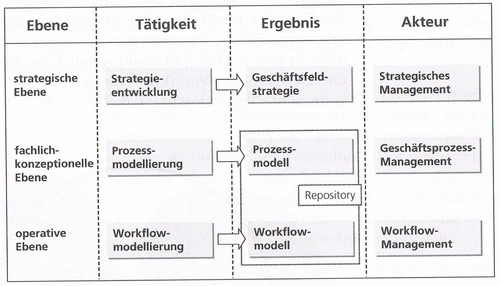
Zunächst werden üblicherweise auf der strategischen Ebene für jedes Unternehmen Strategien entwickelt und Geschäftsfelder definiert.
Dies kann in einem Tageszeitungsverlag die Idee sein, neben dem klassischen Printprodukt auch Online-Veröffentlichungen zu produzieren.
Die Aufgabe auf der fachlich konzeptionellen Ebene ist es nun den Prozess der Produktionen zu definieren und festzuhalten, wie der Prozess ablaufen soll.
Auf der operativen Ebene sind anschließend die Workflow Modelle zu erstellen.
Wie werden uns in dieser Veranstaltung ausschließlich um die fachlich konzeptionelle Ebene kümmern.
Es gibt mittlerweile eine Vielzahl von Methoden zur Modellierung von Geschäftsprozessen und Workflows.
Die Geschäftsprozessoptimierung erfolgt in der Regel durch eine Aufnahme der IST-Prozesse. (Also dadurch, zu schauen, was augenblicklich im Unternehmen vorliegt, welche Prozesse stattfinden.)
Danach werden die SOLL-Prozesse analysiert. (Die Prozesse festlegen, die nachher den optimierten bzw. neuen Prozess darstellen, abgeleitet aus den strategischen Vorgaben der strategischen Ebene.)
Geschäftsprozessmodelle beschreiben den Geschäftsprozess formal. Workflowmodelle hingegen dienen dazu, den Geschäftsprozess detailliert zu spezifizieren und verfolgen das Ziel eine Ausführung durch Workflowmanagementsysteme zu erreichen. Workflowmodelle werden durch Verfeinerung aus den Geschäftsprozessmodellen abgeleitet.
Es ist üblich, Geschäftsprozessmodelle in diagrammbasierten Sprachen darzustellen. Diese lassen sich in drei große Klassen gliedern:
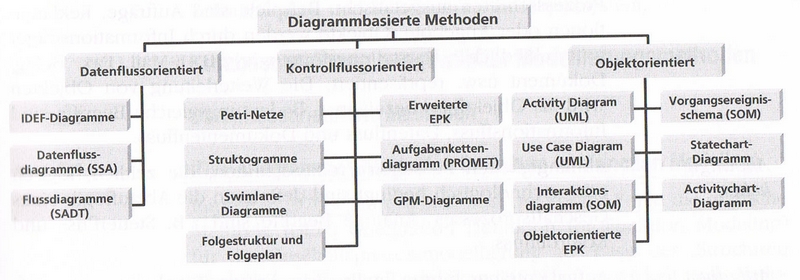
Die datenflussbasierten Methoden wie SADT werden immer selterner eingesetzt. Diese haben wir ja bereits ansatzweise kennen gelernt. Die Struktogramme, die aus der Softwareentwicklung stammen, haben in diesem Einsatzfeld keine Bedeutung erlangt und können ebenfalls vernachlässigt werden.
Sehr starke Bedeutung hingegen haben die kontrollflussorientierten Methoden. Insbesondere die von Keller, Nüttgens und Scheer entwickelten EPKs haben eine große Verbreitung. Sie wurden 1992 auf der Grundlage von Petri-Netzen entwickelt. Da sie recht leicht zu erlernen sind und in der Praxis vielfach als Diskussionsgrundlage zwischen den IT-Spezialisten und den Mitarbeitern in den Fachabteilungen eingesetzt werden, werden wir uns ganz speziell kümmern.
Die objektorientierten Methoden werden als Beschreibungsmethode in der Praxis in erster Linie in Form von Aktivitätsdiagrammen (eine grobe Beschreibung der Prozesse auf hohem Abstraktionsniveau) und als Use Case Diagramme (Zusammenhang zwischen Funktion und Organisationseinheit) eingesetzt. Um diese beiden Formen werden wir uns später kümmern.
Für die Beschreibung von Geschäftsprozessen ist es sinnvoll sich zunächst Gedanken über die Begriffe und das Begriffssystem zu machen. Es muss klar sein, wie die Benennung von Informationen, Tätigkeiten, Ablaufbeziehungen und Zuordnungen geregelt ist. Geschäftsprozessmodelle bilden dabei in der Regel folgende Aspekte ab:
|
Prozessschritte |
Schritte, die zur Erstellung von Prozessleistungen erforderliche Tätigkeiten repräsentieren. Synonym werden die Begriffe Vorgang, Aufgabe, Funktion, und Arbeitsschritt genutzt |
|
Objekte |
Objekte werden in Prozessschritten bearbeitet und zwischen den Schritten ausgetauscht. Beispiele sind Aufträge, Reklamationen oder Angebote. Objekte werden durch Informationsträger unterschiedlicher Darstellungsformen z.B. FAX, E-Mail oder Beleg repräsentiert. Die Weiterleitung von Objekten wird als Objektfluss bezeichnet. Synonym sind Informationsfluss, Datenfluss oder Dokumentenfluss. |
|
Abhängigkeiten |
Hiermit sind zeitliche, logische oder technologische Abhängigkeiten zwischen den Prozessschritten bezeichnet. Sie definieren die Ablauflogik des Geschäftsprozesses. Synonym sind: Steuerfluss oder Kontrollfluss |
|
Aufgabenträger |
Die Aufgabenträger führen in den Prozessschritten Tätigkeiten aus. Typische Aufgabenträger sind neben menschlichen Bearbeitern auch Maschinen oder Programme. Alternativ sind die Begriffe Abteilung, Organisationseinheit, Funktionsträger usw. |

Die Methode der EPKs wurde in Rahmen des von Scheer entwickelten Architekturkonzeptes für die Entwicklung und Beschreibung von Informationssystemen ARIS (Architektur Integrierter Informationssysteme) und der dort implementierten Modellierungskonzepte entwickelt. Dieser Ansatz hat sich in der Praxis mittlerweile als die federführende Modellierungsmethode durchgesetzt. Die Methode ist semi-formal, was soviel bedeutet, dass es zwar eine Menge an Regeln und Vorschriften gibt, allerdings trotzdem Spielräume gelassen werden.
Bevor wir uns die EPKs genauer ansehen, werfen wir einen Blick auf das Gesamtkonzept von ARIS, um zu verstehen, wie die EPKs dort eingebettet sind und welche Rolle sie in dem gesamten Kontext spielen.
Aris unterscheidet in vier sekundäre und eine zentrale Sichten. Die zentrale Sicht ist die
Die vier sekundären Sichten sind die
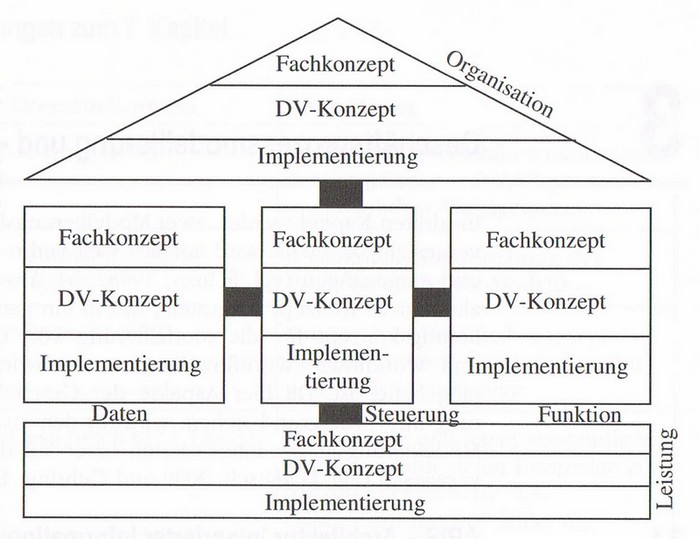
In diesem Aris-Haus werden in jeder Sicht drei Ebenen oder Layer genannt. Diese Ebenen unterteilen die Tätigkeiten, die in dieser Sicht vorgenommen werden in unterschiedliche Kategorien. In der Regel kann man sagen, dass die Ebenen zeitlich in der Abarbeitung von oben nach unten durchlaufen werden.
Diese unterschiedlichen Modellierungssichten benötigen auf die jeweils speziellen Anforderungen abgestimmte Modelltypen. Diese sind ebenfalls von Scheer et al. vorgeschlagen und in das ARIS Haus eingepflegt worden.
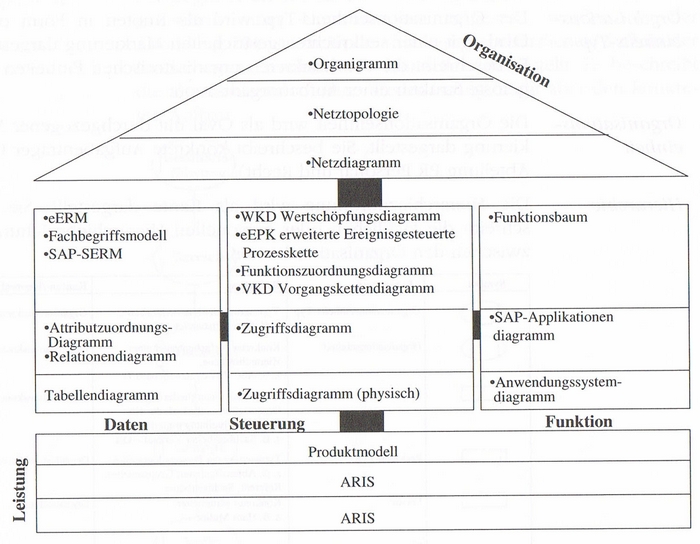
Sehen wir uns verschiedene Sichten und deren Zielsetzungen einmal genauer an. Dabei werden wir auch einige der Notationen kennen lernen und in der Lage sein, einfache Organisationsstrukturen zu modellieren.
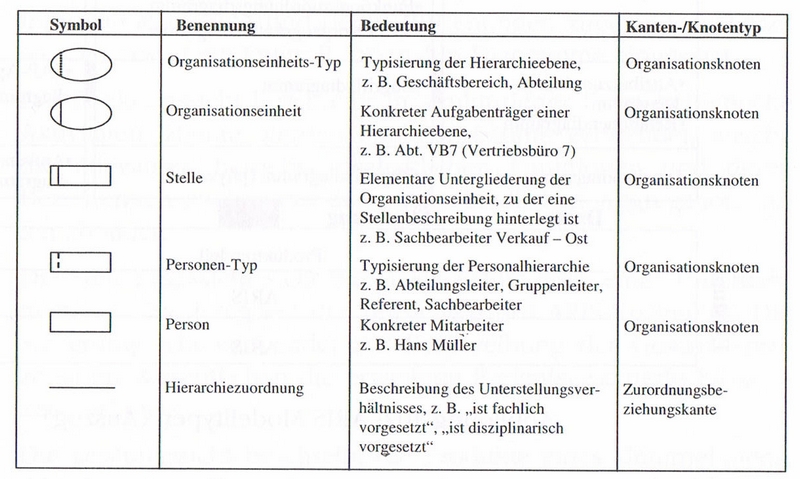
Das Ziel der Organisationssicht ist es, die Struktur und Beziehungen in Organisationseinheiten zu beschreiben. Dabei werden die disziplinarischen und fachlichen Strukturen erfasst. Die Prozessmodellierung wird durch die Zusammenfassung gleicher oder ähnlicher Aufgaben zu Organisationseinheiten, die als Personen, Stellen oder Abteilungen beteiligt sind, erreicht.
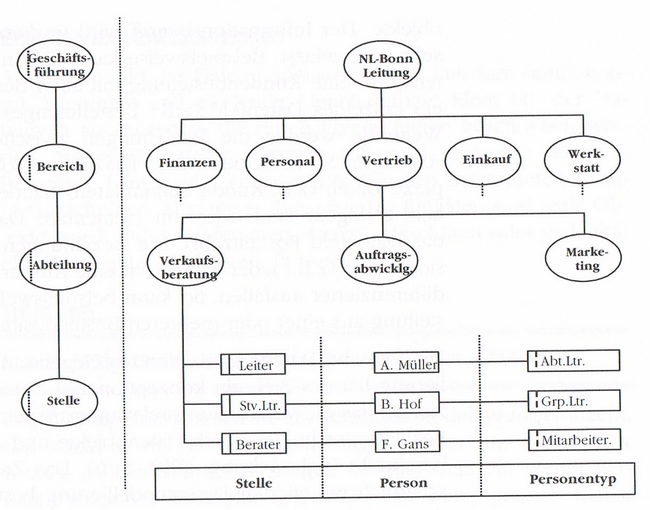
Ein Beispiel für eine Darstellung stellt die folgende Grafik dar. Dabei wurde bereits auf der Ausprägungsebene modelliert. Hier sind im Unterschied zu generalisierten Ebenen Personen explizit genannt.
Aufgabe: Stellen Sie die Organisationsstruktur des Betriebes dar, in dem Sie Ihr Vorpraktikum abgeleistet haben.
Ziel der Datensicht ist es, die Informationsobjekte und deren Beziehung untereinander zu beschreiben. Man spricht hier auch von Datenmodellierung oder von einem Entity Relation Model. Es entsteht ein konzeptionelles Modell, das gegen Veränderungen der Funktionalität weitgehend stabil ist.
Die Datenmodellierung ist etwas komplexer als die Modellierung von Organisationsstrukturen. Aus diesem Grund wird hier lediglich ein kurzer (nicht vollständiger) Abriss gegeben. Die hier vermittelten Inhalte werden Sie sicherlich noch gut in der Veranstaltung Datenbanken verwenden können. Bei den Daten ist es relevant, nicht nur die Daten (Informationsobjekte) und deren Typ aufzuzeigen, sondern auch die Zustandsdaten (Welchen Status hat der Kunde XY) sowie Informationen zu Ereignissen (ist der Kundenauftrag eingetroffen?) beschreiben zu können.
Ausgangspunkt bei der Datenmodellierung sind so genannte Entitäten (Entities). Darunter versteht man eindeutig identifizierbare Elemente der Datenwelt, die durch Eigenschaften beschrieben werden können. Beispielsweise können Kunden als Entitäten aufgefasst werden.
Beispiel: Der Kunde XYZ GmbH mit der Kundennummer 123
Auch andere reale Objekte lassen sich als Entitäten darstellen. Beispiele: Lieferanten, Artikel (Produkte), Maschinen.
Aber nicht nur reale Objekte, sondern auch Gedankenkonstrukte wie Kosten, Preise oder Termine lassen sich als Entitäten begreifen.
Entitäten lassen sich zu Klassen zusammenfassen. In der Informatik geht es ganz häufig um Klassifizierungen, also auch hier. Wenn wir den Kunden mit der Kundennummer 123 betrachten ist er eine einzelne Entität. Alle Kundenbesitzen aber gleiche Eigenschaften, haben beispielsweise eine Kundennummer. Dann können wir Kunden als Entitätenmenge auffassen.
Diese Klassifizierung braucht man, weil man in Datenmodellen sich nicht mit einzelnen Objekten herumschlagen möchte, sondern die Daten standardisiert (also für alle Kunden in gleicher Form) vorhalten will. Was dann mit den Daten dieser Entitätsmenge passiert, ist von den verschiedenen Ausprägungen unabhängig.
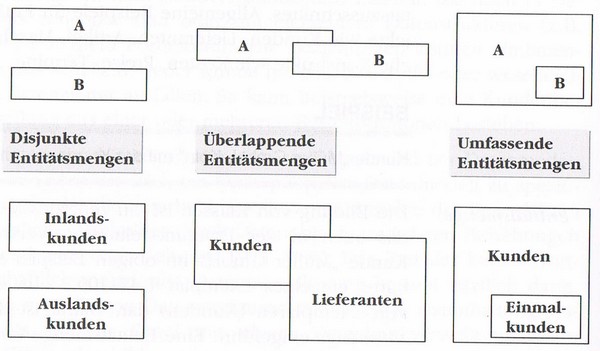
Diese Entitätsmengen müssen immer gleiche Eigenschaften besitzen. Wenn mehrere Entitätsmengen gebildet werden müssen diese aber nicht zwangsläufig durch komplett andere Eigenschaften beschrieben werden. Wenn dem jedoch so ist und die Mengen nicht gleichzeitig auch in anderen Mengen verwendet werden spricht man von disjunkten Entitätsmengen.
Nicht disjunkte Entitätsmengen hingegen überlappen sich. So kann beispielsweise ein Kunde auch als Lieferant auftreten.
Es kann sogar sein, dass eine Entitätsmenge eine andere vollständig umschließt. So kann z.B. die Entitätsmenge Einmalkunde zur übergeordneten Entitätsmenge Kunde gezählt werden.
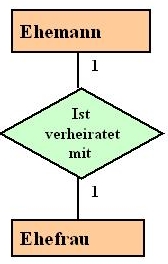
Die verschiedenen Entitäten stehen möglicherweise in Beziehung zueinander. Hierfür hat sich eine Notation durchgesetzt, um diese Beziehung (oder auch Relation) zu beschreiben.
Nehmen wir als klassisches Beispiel an, es gäbe eine Entität Ehemann und eine Entität Ehefrau. Diese beiden sind, zumindest in westlichen Kulturkreisen, als eine 1:1 Beziehung in Relation zu setzen.
Als Name für eine Entitätsmenge ist ein Substantiv im Singular zu wählen, z.B. Ehemann, Kunde, ...
Als Name für eine Assoziation sollte ein Verb im Singular gewählt werden, z.B. ist verheiratet mit,...
Die Entitätsmengen werden als Rechtecke dargestellt.
Die Assoziationen werden als Rautensymbol dargestellt. Diese Rautendarstellung einspricht der Chen Notation. In der vereinfachten Notation entfallen diese Rauten und Assoziation wird direkt auf die Kante (die Linie) geschrieben.
Das es hier eine 1:1 Beziehung gibt, wird durch die so genannten Kardinalitäten angezeigt. Es handelt sich um die kleinen Beschriftungen auf den Linien.
Nun kann es aber ja auch sein, dass die Beziehung (die Kardinalität) zwischen den Entitätsmengen eine andere ist. Die Kardinalität gibt an, mit wie vielen Entitäten einer Entitätsmenge eine bestimmte Entität in Beziehung steht.
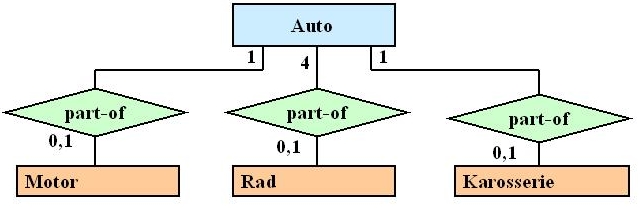
Diesen Satz muss man langsam verdauen. Deshalb gleich ein Beispiel: Ein Auto lässt sich als eine Aggregation, bestehend aus einem Motor, 4 Rädern und einer Karosserie, beschreiben. Ein Motor kann für sich allein stehen (noch nicht eingebaut und damit noch keinem Auto zugeordnet) oder Teil eines Autos sein, daher die Kardinalität 0,1 (numerische Notation).
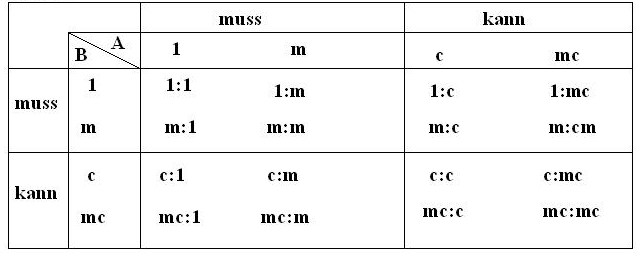
Die verschiedenen Assoziationen sind hier nochmal tabellarisch aufgeführt:
|
Kardinalität (A,B) |
Notation kurz |
Notation lang |
Anzahl Entitäten von B, die der Entität A zugeordnet werden können |
|---|---|---|---|
|
einfach |
1 |
[1,1] |
genau eine (1) |
|
konditionell |
c |
[0,1] |
eine oder keine (c=0 oder c=1 |
|
multiple |
m |
[1,n] |
eine oder mehrere (m≥1) |
|
multiple - konditionell |
mc |
[0,n] |
keine, eine oder mehrere (mc≥0) |
Durch diese Notation kann es zu 16 verschiedenen Kombinationen von Beziehungstypen von 2 Entitätsmengen kommen.
Aufgabe: Stellen Sie die Beziehung zwischen den Entitätsmengen "Vorlesung Einführung in die Informatik" "Studierende" und "Dozenten" mit gültigen Assoziationen her.

Die Attribute beschreiben die Eigenschaften einer Entitätsmenge. Dabei muss natürlich darauf geachtet werden, dass die einzelnen Entitäten auch die gleichen Eigenschaften haben. Wenn wir als Beispiel die Entitätsmenge "Studierende" hernehmen, so besitzt jede Entität die Eigenschaften: Matrikelnummer, Vorname, Nachname, Fachbereich, Studiengang, Studiensemester
Wenn Sie jetzt für die Attribute konkrete Angaben machen, sind dies die Werte, die konkreten Ausprägungen, einzelner Entitäten.
Sie haben vielleicht schon festgestellt, dass Ihre Matrikelnummern eine feste Länge haben. Diese festen Wertebereiche lassen sich über so genannte Domänen festlegen. So kann für die Matrikelnummer beispielsweise ein Wertebereich [100000 - 999999] festgelegt werden.
Attribute können einen beschreibenden Charakter haben oder zusätzlich die Entität identifizieren. Die identifizierenden Attribute bezeichnet man auch als Schlüssel. Nun kann es sein, dass ein Attribut, wie hier im vorliegenden Fall die Matrikelnummer, ausreicht. Dann nennen wir es einen "einfachen Schlüssel". Werden mehrere Attribute zur Identifikation benötigt, handelt es sich um einen "zusammengesetzten Schlüssel". Die identifizierenden Schlüssel werden durch Unterstreichung gekennzeichnet.
Mit den gerade erlernten Methoden lassen sich Zusammenhänge über das Entity Relationship Modell gut beschreiben. Dieses Modell wurde von P. Chen bereits 1976 entwickelt. Er hat es benötigt, um damit ein Datenmodell für permanent gespeicherte Daten aufzustellen.
Das Beispiel zeigt ein einfaches ERM. Es wird hier dargestellt, dass ein (Zeitungs-)Artikel in einer Ausgabe einer Zeitung erscheint. Dabei erscheint natürlich ein bestimmter Artikel nur in einer Zeitungsausgabe, aber in einer Ausgabe erscheinen mehrere Artikel. Ein Kunde liest entweder eine Zeitungsausgabe, mehrere Zeitungsausgaben oder gar keine.
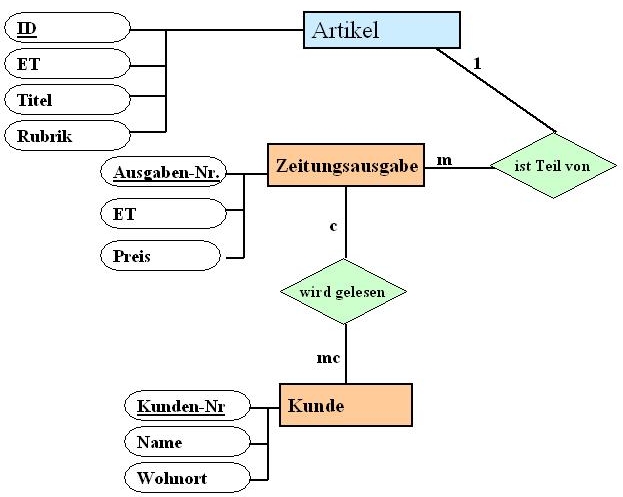
Um sicher zu gehen, dass das Modell korrekt ist, sollte man folgende Überprüfungen durchführen:
In der Systemanalyse kann man auf einem angemessenen Abstraktionsniveau aufhören z. B. bei Adresse und ein solches Attribut als elementar ansehen. Abhängig vom Blickwinkel können Attribute zu Entitätsmengen werden und umgekehrt.
Aufgabe: Erstellen Sie ein ERM für folgende Situation: Ein Vertriebsmitarbeiter betreut einen oder mehrere Kunden. Jeder Kunde wird von genau einem Vertriebsmitarbeiter betreut. Ein Produkt wird von einem oder mehreren Kunden gekauft. Die Kunden können entweder kein, ein oder mehrere Produkte kaufen.
Die Funktionssicht hat das Ziel zu klären, wie Geschäftsprozesse strukturiert sind, welche Aufgaben und Prozesse durch welche Teilfunktionen unterstützt werden und Welche Funktionen die Geschäftsziele unterstützen.
In dieser Sicht geht es darum, die betriebswirtschaftlichen Funktionen und deren Beziehung zueinander zu beschreiben.
Um diese Sicht etwas besser zu verstehen, müssen wir uns zunächst klar machen, was eine Funktion überhaupt ist.
Das wesentliche Merkmal einer Funktion ist, dass sie den Zustand eines Objektes ändert. Dies sind in der Regel fachliche Aufgaben, die ein Objekt von einem Eingangszustand in einen Ausgangszustand überführen.
Simples Beispiel: Eine Transformation einer Bilddatei (Objekt) von einem Format in ein andres Format ist eine Funktion.
Weiteres Beispiel: Eine Funktion kann auch das Objekt belassen, aber seine Eigenschaft ändern: Ein Beleg (Objekt) geht durch eine Funktion (Beleg buchen) von einem Zustand in einen anderen Zustand über.
Funktionen können in der Regel in Teilfunktionen zerlegt werden. Teilfunktionen können wiederum in elementare Funktionen zerlegt werden. Elementare Funktionen sind Funktionen, die nicht weiter zerlegt werden können.
Ein Beispiel für die Zerlegung von Funktionen:
Nehmen wir als Objekt wieder eine Bilddatei an. Als Funktion können wird "Bild bearbeiten" definieren. Eine Teilfunktion wäre beispielsweise "Format ändern". Eine elementare Funktion ist dann "Bild speichern".
Über diese Funktionen können wir nun einen Funktionenbaum erstellen und die Funktionen hierarchisch anordnen.
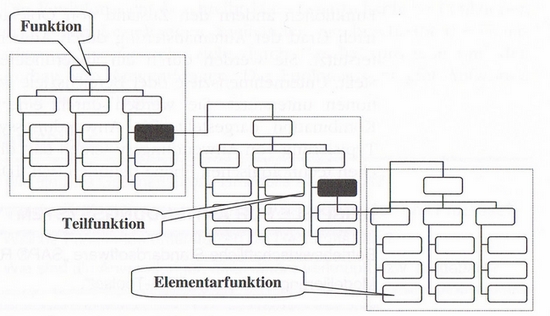
So kann erreicht werden, dass klar wird, welche Funktionen zusammen gehören und in welchen Abhängigkeiten zu zueinander stehen.
Die Verrichtung von Funktionen findet häufig mit der Hilfe von Anwendungssystemen statt. Dies sind, einfach formuliert Computerprogramme.
Die Leistungssicht wollen wir nur sehr kurz behandeln, zumal dieses Thema vorwiegend kaufmännische Vorgänge beschreibt. Die Leistungssicht beschreibt nichts anderes als die materiellen und immateriellen Input- und Output-Leistungen inklusive der Geldflüsse.
Nun ist Geld nicht alles und deshalb werden mit der Leistungssicht auch Sach- und Dienstleistungen beschrieben. Den Begriff Leistung können wir auch mit dem Begriff Produkt gleichsetzen.
Viel interessanter ist für uns die Steuerungssicht. Mit dieser Sicht werden die anderen Teilsichten zusammengeführt.
Die Steuerungssicht bedient sich dabei den Instrumenten der Wertschöpfungskettendiagramme (WKD) und der ereignisgesteuerten Prozesskette (EPK).
Die WKD ist in unserem Zusammenhang nicht relevant. Die EPK hingegen ist so interessant, dass wir ihr ein eigenes Kapitel widmen.
Die Steuerungssicht beschreibt den Geschäftsprozess im Ganzen in ist damit das zentrale Mittel des ARIS-Konzeptes.
Wenn wir also das ARIS - Konzept insgesamt beschreiben wollen, können wir abschließend sagen, es handelt sich dabei um einen prozessorientierten Ansatz zur Beschreibung der Unternehmensorganisation und der Architektur betrieblicher Informationssysteme.